在课题组要做报账,那么就免不了根据发票做出入库单,东西少的时候还好,一多起来真的麻烦死人。所以在我还在参与报账工作的时候我就做了一个小工具,可以很畅快地做出入库单,界面如下图:
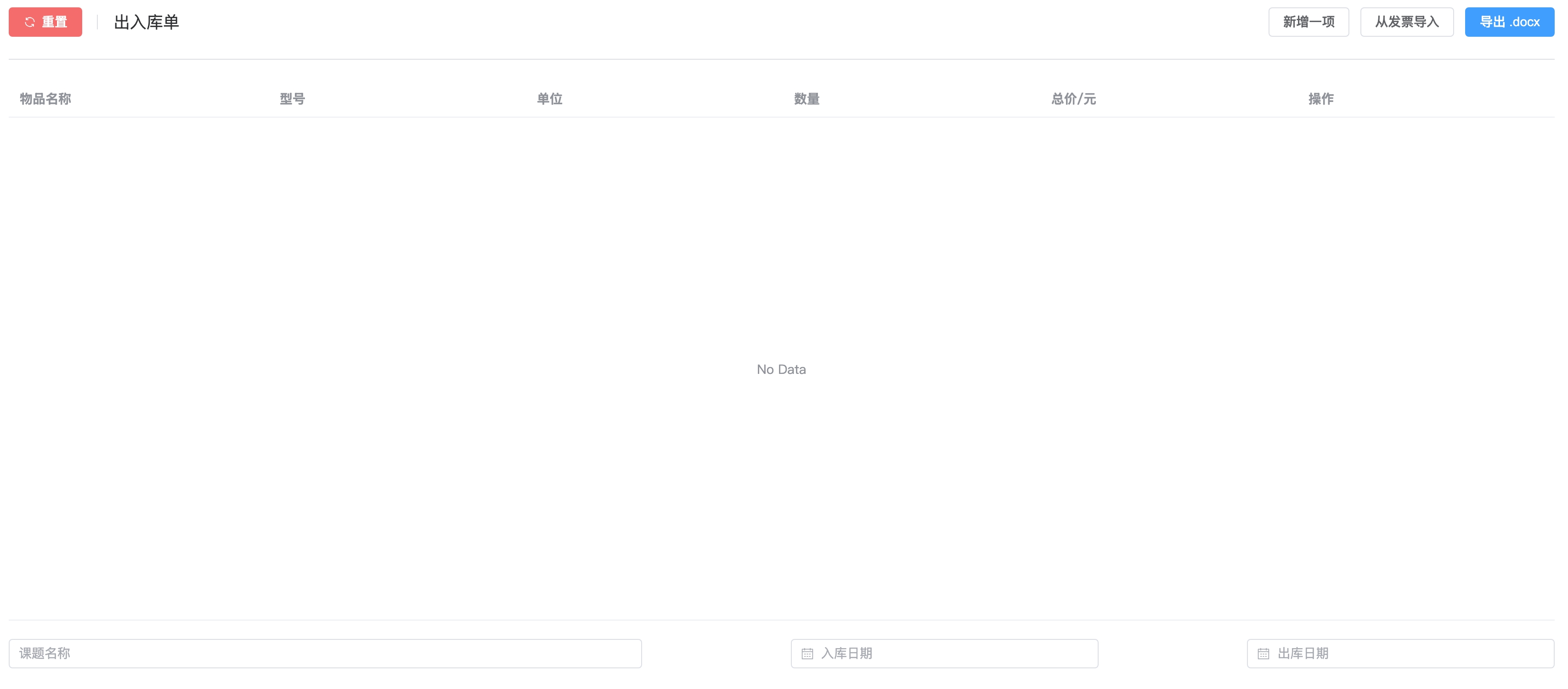
虽然减少心智负担了,但是这个时候依旧是需要手动输入发票号码、代码、开票日期等信息。现在没有参与报账工作了,突然想到要是能直接上传文件就获得所有发票信息该多好,说干就干。最初的项目是js/ts一把梭,这次改用Python,毕竟人生苦短,我用Python。
提取发票信息的主体代码实现如下,主要依赖pdfplumber这个库和正则表达式:
python
import pdfplumber
import re
from typing import List, Dict, Optional
class InvoiceExtractor:
def _invoice_pdf2txt(self, pdf_path: str) -> Optional[str]:
"""
使用 pdfplumber 从 PDF 文件中提取文本。
:param pdf_path: PDF 文件的路径。
:return: 提取的文本作为字符串返回,如果提取失败则返回 None。
"""
try:
with pdfplumber.open(pdf_path) as pdf:
text = '\n'.join(page.extract_text() for page in pdf.pages if page.extract_text())
return text
except Exception as e:
#print(f"从 {pdf_path} 提取文本时出错: {e}")
return None
def _extract_invoice_product_content(self, content: str) -> str:
"""
从发票文本中提取商品相关内容。
:param content: 发票的完整文本。
:return: 提取的商品相关内容作为字符串返回。
"""
lines = content.splitlines()
start_pattern = re.compile(r"^(货物或应税劳务|项目名称)")
end_pattern = re.compile(r"^价税合计")
start_index = next((i for i, line in enumerate(lines) if start_pattern.match(line)), None)
end_index = next((i for i, line in enumerate(lines) if end_pattern.match(line)), None)
if start_index is not None and end_index is not None:
extracted_lines = lines[start_index:end_index + 1]
return '\n'.join(extracted_lines).strip()
return "未找到匹配的内容"
def construct_invoice_product_data(self, raw_text: str) -> List[Dict[str, str]]:
"""
处理提取的文本,构建发票商品数据列表。
:param raw_text: 提取的原始文本。
:return: 商品数据列表,每个商品为一个字典。
"""
blocks = re.split(r'(?=货物或应税劳务|项目名称)', raw_text.strip())
records = []
for block in blocks:
lines = [line.strip() for line in block.splitlines() if line.strip()]
if not lines:
continue
current_record = ""
for line in lines[1:]:
if line.startswith("合") or line.startswith("价税合计"):
continue
if line.startswith("*"):
if current_record:
self._process_record(current_record, records)
current_record = line
else:
if " " in current_record:
first_space_index = current_record.index(" ")
current_record = current_record[:first_space_index] + line + current_record[first_space_index:]
if current_record:
self._process_record(current_record, records)
return records
def _process_record(self, record: str, records: List[Dict[str, str]]):
"""
处理单条记录并添加到记录列表中。
:param record: 单条记录的字符串。
:param records: 记录列表。
"""
parts = record.rsplit(maxsplit=7)
if len(parts) == 8:
try:
records.append({
"product_name": parts[0].strip(),
"specification": parts[1].strip(),
"unit": parts[2].strip(),
"quantity": parts[3].strip(),
"unit_price": float(parts[4].strip()),
"amount": float(parts[5].strip()),
"tax_rate": parts[6].strip(),
"tax_amount": float(parts[7].strip())
})
except ValueError as e:
print(f"记录解析失败: {record}, 错误: {e}")
pass
最终呢会得到一个字典,包含了发票的商品名、规格、单位、数量、单价、总价、税率以及税额。紧接着,基于这段脚本,再结合fastapi和vue3,就搞了一个拖拽就能获取发票信息、导出出入库单的应用啦:
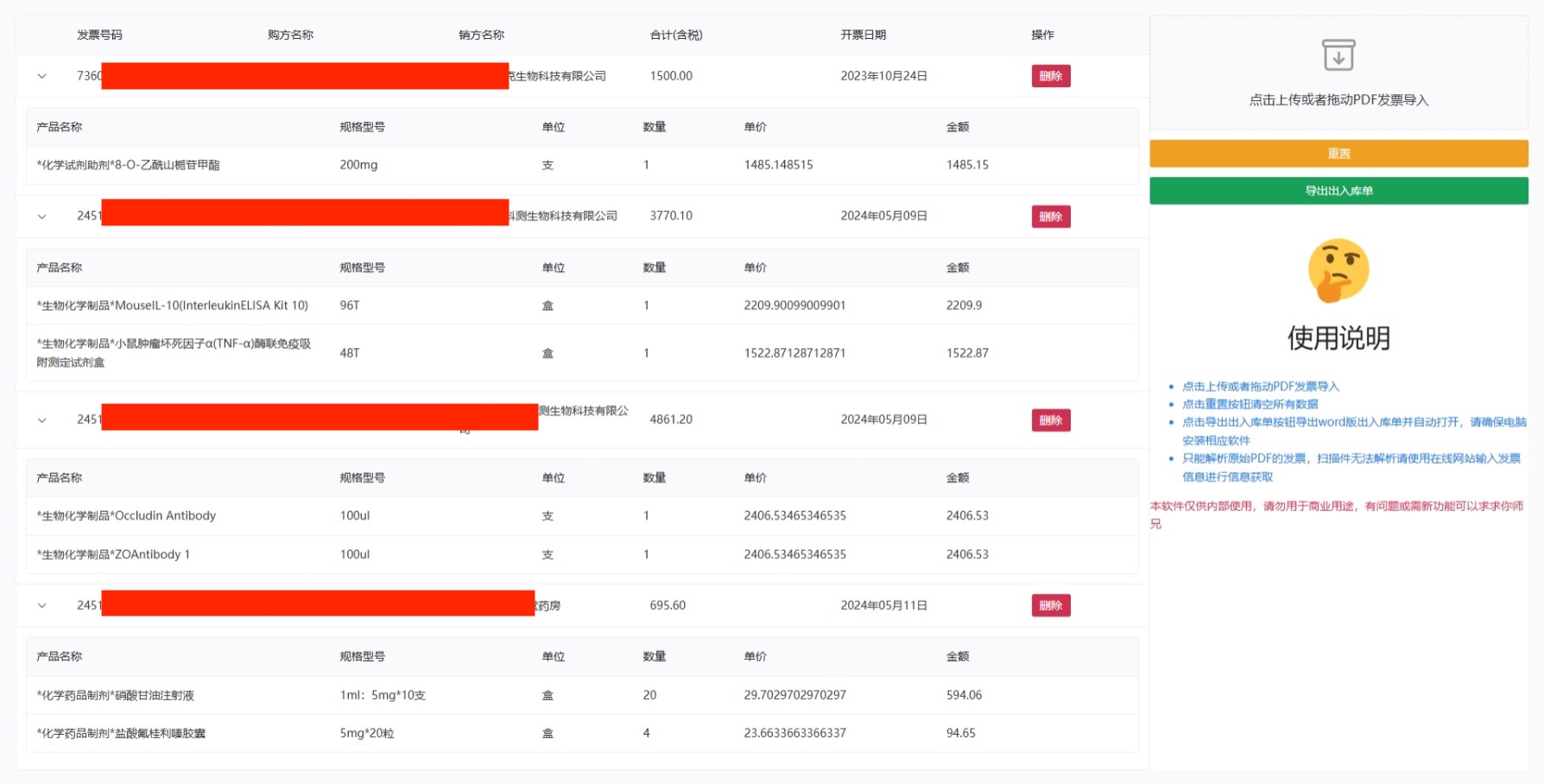
当然,我现在又不负责报账的工作了,做出来也是造福师弟师妹们,管他们用不用,反正我做出来了